Shawn Wang / swyx
Interview occurred in February, 2022. Read more from Shawn on his blog, twitter, and his book, The Coding Career Handbook.
Tell us a little about your current role: where do you work, your title and generally the sort of work you and your team do.
I’m currently Head of Developer Experience at Temporal.io, an open source workflow engine for long running, durable processes powering companies as small as 2-person YCombinator startups, to enterprises as large as Stripe, Snap, Datadog, Netflix, Doordash, etc. We are generally responsible for improving the experience of “front line” individual contributor developers, covering their end to end journey from first contact (DevRel) to learning (Docs) to API Design (SDKs) to ecosystem (Community).
The basic insight is that companies ship their org charts (Conway’s law), but developers don’t care what team shipped which when they go through your product, so it makes sense to have someone whose job it is to coordinate and build out developer-facing efforts cohesively.
In Developer Exception Engineering, you wrote a bit about the slipperiness of defining “developer experience,” and how it often varies significantly across companies. How would you explain developer experience to someone unfamiliar with the role?
Developer Experience (DX) is a buzzword at this point, so naturally everyone is co-opting it to represent their particular view of the world, making it extra confusing for anyone that just wants a straight answer. But I’ll give you my best shot here.
At the highest level, the basic dichotomy to be aware of is “internal” vs “external” DX. Most people who come up within one of these two branches may be completely unaware of the other, which contributes to the confusion when people discuss “DX”.
Internal DX teams focus on developer productivity within a company (sometimes called “dev infra”). The math is simple - if you have 50 engineers, and you think it’s possible to improve their productivity by >1% a quarter, then you would be silly not to invest in 1-2 engineers who don’t work on product, but just focus on making everyone else more productive. Scale this up to a 1000 engineer company and you now have a whole Internal DX org to play with. They can span a wide range of deliverables, from build/test automation to dev environment to code quality. The clearest mental model for identifying Internal DX opportunities I’ve come across is Netflix’s Productivity Engineering team, which is responsible for three major components - from new hire to productive local dev (their Bootcamp and bootstrapping tool, NEWT), from local dev to production (their “build-bake-deploy paved road”), and then from production back to dev (their observability tools like Atlas). The other popular taxonomy to work with are the four Accelerate metrics. Both of these approaches essentially divvy up the software development lifecycle into meaningful chunks, which can then be independently and tangibly improved by internal DX teams.
External DX teams focus on improving developer adoption/mindshare/productivity at other companies. Where almost any software company can have Internal DX, it only really makes sense to have External DX if you make something for developers. This means it is a natural fit for devtools companies, but you might be surprised at what companies invest in this. Are Spotify, Notion and Slack devtools companies? No… but they all offer APIs for developers! So they all have DevRel teams. The distinction between DevRel (also known as Dev Advocacy) and DX is another common question. On one hand, traditional DevRel is very heavy on content creation (blogging and speaking, basically, but also demos and workshops), whereas DX has more of a mandate to write (non-core) code and docs to solve problems. I first transitioned from DevRel to DX at Netlify, where eventually it formally covered Advocacy, Integrations, and Documentation. The exact coverage will naturally differ based on the product - for example, Netlify is a closed source SaaS platform, so Advocacy plays a bigger role, whereas Temporal is an open source client-server system, where equal love needs to be given to Community and Docs.
A quick aside for those who often hear DevRel vs DX conflated: DX is supposed to be the superset, but frankly, the lion’s share of DX is still DevRel, for both economical and historical reasons. Economical, because most developers know how to build product, but are terrible at building distribution, so a DX team often contributes the most value by reaching developers despite all the other things on its plate. Historical, because the DevRel to DX transition is a once-in-a-lifetime career upgrade for Dev Advocates to have more impact, just like the Sysadmin to DevOps transition. It all makes sense once you consider that Dev Advocates speak the most to users, but usually have the least power to make fundamental changes to solve their pain, particularly those I term “Developer Exceptions” in that blogpost. Blogposts and talks have a half-life far shorter than docs and tooling/product improvements.
Once you’ve marinated in the various aspects of DX enough, the distinctions start to re-blur once you consider that Internal DX just serves internal customers (and needs to invest in docs and advocacy too), and External DX serves external ones (and needs to tangibly improve productivity too). Both roles require a great deal of empathy with developer problems, and an expansive mental catalog of ways to solve them. Yet the ultimate relevance of either to the outside world matters only to the extent of a typical build-vs-buy decision. Don’t get too hung up on precise definitions in an inherently fuzzy and still-moving field.
When we first discussed this interview, you asked if your experience would be interesting to folks focused on infrastructure engineering. I’ve increasingly come to believe that Developer Experience is a core competency for all folks developing infrastructure software or working on infrastructure projects like large-scale migrations. Should infrastructure teams consider Developer Experience as a core engineering competency? Any ideas why they often don’t?
It’s funny, even though I do DX at a company that serves Infra engineers now (and Temporal enables Infra engineers to offer a dramatically better developer experience to product teams by providing “reliability on rails”), I had never ever viewed it as something Infra engineers themselves should regard as core. For sure, the Derisk-Enable-Finish cycle in that article on Migrations leans on many of the same skills as DX teams - advocacy, docs, tooling. But I’m loath to recommend that it should be “core” in all contexts, because (as we discussed earlier) DX is so broad and hard to define, and I’m always skeptical of people hawking their pet topic as mandatory. A bloated definition of “core” defeats the purpose of defining a “core”.
What I will say is that I think most Infra Engineers could do with more developer empathy, which in most situations simply means putting themselves in the shoes of people with less context and knowledge than them and proactively helping them out by any means necessary. If you do it right, then yes, the developer experience of your users will be better because you took the effort, but it should be done not for altruistic “let’s make them happy” reasons, but rather, selfish ones: your efforts will be more successful if they feel more successful.
Why don’t more infra teams invest in Developer Experience? Honestly, probably because there’s no cultural expectation for them to. It’s common for infrastructure teams to get consumed by the loudest issues surrounding them like incidents and infrastructure costs such that they end up much more focused on their obligations to computers than their obligations to other engineers.
What are the top three tools or techniques that you use in Developer Experience that infrastructure engineering teams should consider adopting?
- Journey Mapping: exhaustively enumerate every concept, system, or API capability your user should know (thereby letting people know what they don’t know). Pick 2 main axes of concern and map them out in 2D space - clustering related concepts together. Draw a small core of “must know” concepts where everyone should start (letting people know what they don’t need to know). Identify and highlight FAQs. Then let them find their way based on their needs. This contrasts with a “one size fits all” linear path. (see example)
- Pitch Sizing: Be prepared to explain/define your system in one sentence (pique interest), one paragraph (by desired requirements or by pitching the problem), a 10 minute presentation, or a 30 minute demo. Logical/technical arguments are best supplemented with Cialdini persuasion principles. Practice this when you don’t yet need it (eg at internal demo day/lunch) because you will be called upon to do it at the most unexpected times for the most high leverage reasons.
- Two phase commit: Knowledge is transferred as both discrete particles and continuous waves. Concretely, some of your users will want a monolithic organized reference, and others will just want diffs. One example rule that implements a “two phase commit” of knowledge - Every feature update should be communicated via a changelog and a doc/wiki update (and, for more impactful updates, a tweet, slack message, blogpost, talk…).
- (Bonus) Events: Learning to throw events that people look forward to and enjoy participating in is a huge multiplier on existing DX efforts. (see Community Annealing)
Infrastructure engineering organizations have a lot of priorities. A few years ago I tried to define an overarching set of infrastructure priorities and came up with: security, reliability, usability, leverage, cost and latency. I imagine this is at least equally true for DX teams, how do you figure out what to work on given the wide range you could prioritize?
I think about DX work in terms of concentric circles radiating out from the core product, matching the maturity of the product:
- When the product is still being shaped, there is no better time to give feedback on API design.
- As the product approaches fully baked, I shift my attention to Docs.
- After shipping the product with a complete set of docs, I shift to Content (Advocacy) to get users and to spell out and elaborate whatever doesn’t tonally or structurally fit in docs.
- Users come for the content, and stay for the Community, so I start investing in getting to know them, helping them in their adoption, and find/build for/hire each other.
On and on pushing outward when we can, but looping back inward whenever a new feature or product is launched or a new problem is found.
All of these efforts should be coordinated with the same “map” I described above - shared terminology, shared understanding of core concepts, and a shared reality of neighborhoods and landmarks. However they are not equal in all contexts, because inner circles tend to have higher long term impact (the best docs are the docs I don’t have to read because the product teaches me as I go, the best blogposts are the blogposts I don’t have to look for because the documentation was good enough, etc.), but outer circles have more reach.
What I’ve described is from my experience in my sweet spot at early stage, Series A-C devtool startups, where each program is usually a singleton, but there are advanced versions of this at the larger companies too:
- Every SDK can always have more languages and devtooling.
- Every conference can be replicated across the major continents.
- Every docs effort eventually morphs into a “University” or a certification/education program.
At AWS scale, we also layered the DX circles with language, geographical, and business vertical dimensions. If you wanted a Chinese speaking Telcos specialist in Australia, we had someone for that.
Folks working on infrastructure engineering often have a specific dashboard they look at every morning to get a sense of how the software, system, and organization is operating. Do you have a similar dashboard? What’s on it?
We use a mix of internal BI tools for lagging indicators (active clusters, SDK version adoption) and Common Room for leading indicators (open source and community activity). As long as everything is trending up on a trailing 2-3 month basis I’m not too concerned about checking it every day. Considering that it takes >10 touches for the average person to go from first contact to seriously interested, the natural frequency of consideration cycles make for extremely long feedback loops.
This is further confounded by the extremely non-ergodic nature of the open source enterprise customer, where one large customer can be worth 5 orders of magnitude more than the median, and take anywhere from a month to two years to convert to a customer.
Most DX metrics are better regarded as a health check that things aren’t broken, rather than proof positive that things are actually working well. If you need more specifics, I’ve received very positive feedback on my piece on Measuring Developer Relations.
OK, I’m going to start turning the conversation towards Temporal for a bit. In every infrastructure team I’ve worked on there’s a team focused on supporting services that offer an API, but it’s often only much later that there’s any support for workflows (by which I mean scheduled, periodic or event-driven tasks) outside of something like Airflow for batch processing. How did Temporal decide to focus on a workflow engine?
There was no decision so much as it was a lifelong obsession borne out of decades of distributed systems experience at scale, and solving the same problems over and over again. My basic insight is that everyone converges on the same requirements for reliability, observability, and scalability in their systems, but the tools we have are too low level, so everyone handrolls (poorly) their own distributed system out of these tools. Eventually, large-enough companies build their own workflow engines to slow the wheel-reinvention.
Our cofounders had been working on various iterations of messaging services and workflow engines for the prior ~20 years, at AWS, Google, Microsoft, and finally Uber. They created Temporal’s precursor at Uber, which became a full-time job as the number of applications using it ballooned to 300 in 3 years. This work was open sourced and similar growth was seen at Hashicorp, Coinbase, Airbnb, Doordash, etc. Finally, demand for a hosted solution was so strong, and the Uber-specific tech debt was so high, that they forked the project to start Temporal. So at every step of the journey the market demand drove the next phase of adoption, rather than any one decision.
Temporal is at once a 2 year old startup and a 20 year old team in this sense; and having that much big tech and open source validation gave us a lot of conviction that the industry is hugely underappreciating the use cases of a workflow engine beyond simple scheduled jobs. There’s a bunch of hypey hyperbole thrown around: “distributed system in a box”, “reliability on rails”, “distributed application state platform”, “a new computing primitive”, “service mesh for long running operations” - all of which are true depending on your point of view.
In listening to Stripe’s talk on Temporal and Netflix’s talk on Temporal, both mention writing their own SDK wrapper on Temporal’s SDK. Is it a good or bad sign when your users routinely wrap your SDK?
It’s easy to map out the pros and cons:
- It’s good in that it validates that we solve a hard enough problem that people wrap us rather than build us… for now. And it gets us users that closed source SaaS and inextensible “No Code” platforms would not.
- It’s bad in that it means our users have a built in facade that makes it easier for them to move off us in the future
- It’s good in that both Stripe and Netflix talk about their wrappers solving company specific problems and providing good defaults for their intended users, that we can later absorb into core once validated enough in “userland”
- It’s bad in that we don’t do some things for them out of the box… yet.
Ultimately I view “being wrapped” as a natural, net positive outcome of any valuable enough devtool. The best thinking I’ve come across on this is Kevin Kwok’s view of platforms vs their ecosystems:
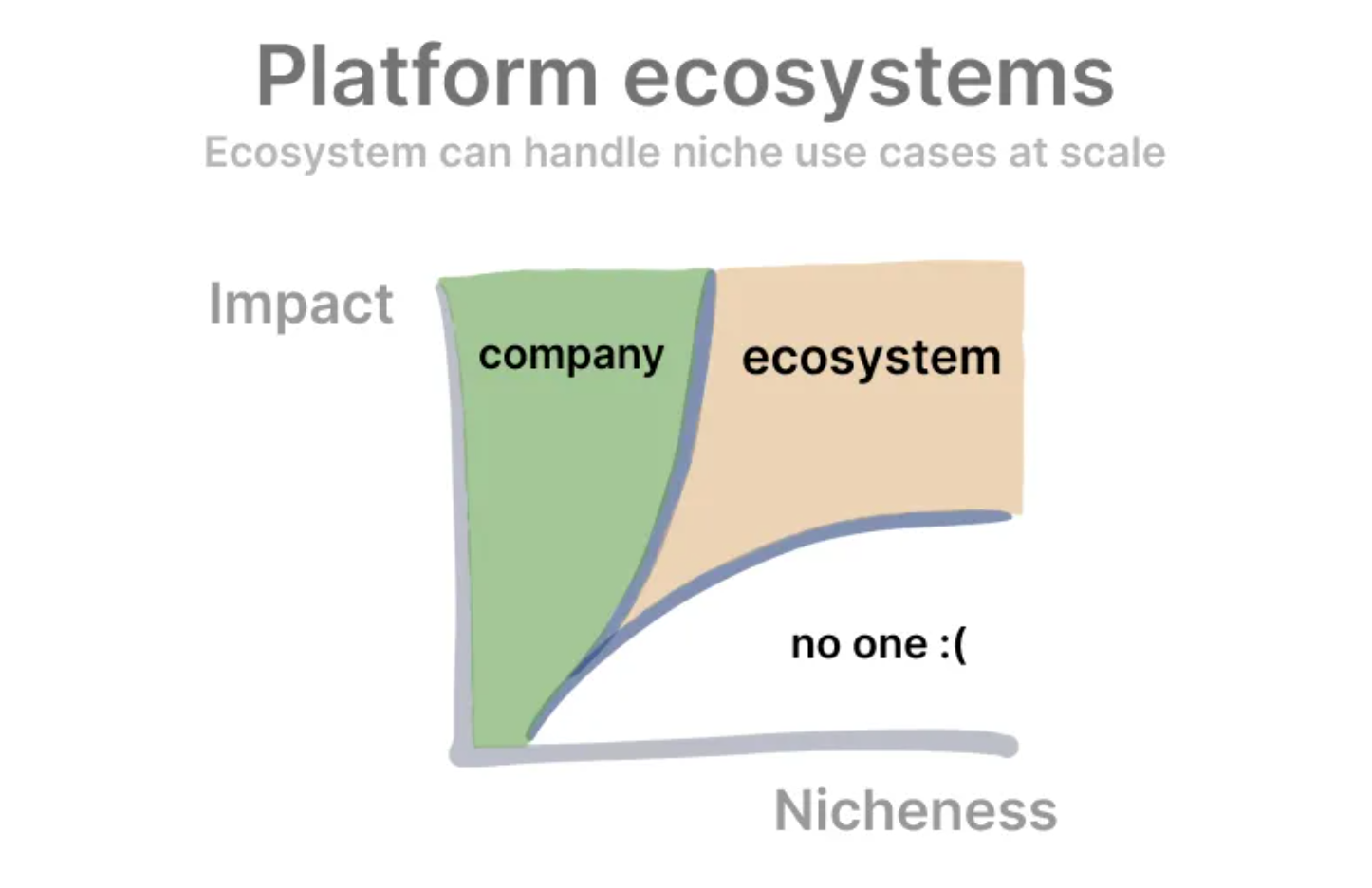
Usecases that are high impact and generally useful should be solved by us, whereas usecases that are lower impact and very specific should be solved by wrappers. We would look to our growing ecosystem to help solve high impact, high niche usecases, and investing in an open source community directly contributes towards this long term advantage.
Since Stripe moved to base generating SDKs off their OpenAPI spec, I’ve started to suspect that SDKs are better interfaces to expose to users than APIs themselves. Are SDKs better user-facing interfaces than APIs?
This is very close to my heart! The simple response is that yes, if you can afford to, offering an SDK (or a CLI, by the way) generally provides a better developer experience than just the raw API. The basic argument is that if you don’t provide an SDK, the developer will eventually have to build one for themselves for anything of sufficient complexity. There are a number of problems that can only be solved at the SDK level, including providing more specific types or type inference, inline documentation/autocomplete, and mocking out the API for testing.
However a poorly implemented SDK can also introduce an extra layer of potential bugs and performance issues, constrain advanced users, cause uncertainty about exposed classes and data structures, and add complexity to versioning/upgrades. In scenarios like these, being able to “drop down” a layer to the underlying API is crucial and the platform should not actively obstruct that.
One should also distinguish between “Fat” and “Thin” SDKs. “Thin” SDKs are simple, 1:1 language wrappers over APIs, the kind that can be generated from OpenAPI. “Fat” SDKs do more, often managing state (e.g. AWS’s AppSync SDK creates a local replica of your DynamoDB backed database, and handles offline sync and merge conflicts), or allowing plugins, or as Temporal’s SDK does, offering a deterministic sandbox which can replay events through your code for failure recovery and durable async functions.
In short, the opportunities for “Fat” SDKs to improve developer experience well beyond simple RESTful APIs are greater, at the cost of more engineering (and docs, and support…) to maintain them. Tradeoffs everywhere!
In The Self Provisioning Runtime, you modify Alfred North Whitehead’s quote saying, “Developer Experience advances by extending the number of important problems our code handles without thinking of them.” That quote gets at the long-term promise of cloud providers, which are slowly making important problems invisible for many users, e.g. my experience is that general awareness of networking is significantly lower than it was a decade ago, which I attribute largely to cloud adoption. In some ways I see Temporal as competing with cloud providers’ own workflow engines. How do you think about competing with the cloud?
I’m excited by it. We certainly have to take it seriously, because Temporal is MIT-licensed, and there is nothing stopping Amazon or Azure from hosting us as a service tomorrow. But at this point dozens of open source companies have faced that threat and survived - by relicensing, and by serving their customers better than the big clouds can. On one hand, this is intimidating, because Amazon theoretically has infinitely more resources to crush us. On the other - I’ve worked at Amazon and seen how hard it is to push through the absolute mountain of conflicting priorities and legacy tech to get anything done compared to tiny startup teams with a fraction of our funding.
This is why topics like developer experience are so important - there are so many more dimensions to building a successful developer infra business than just the commodity operation of software - but I am actually most excited about outcompeting the big clouds by better product strategy and better network effects as those are sustainable and compoundable wins.
I can’t be too specific here but consider how Snowflake made an independent case for itself by being the “Data Cloud”, Cloudflare is doing the same for the decentralized cloud, and Stripe being payment rails for ecommerce. All are justifiably market positions that the big clouds will not/can not tackle given their current strategies. Temporal happens to occupy a very nice space:
- managing lightweight application state, not egress-heavy data
- having a small well defined contract with every mission-critical microservice in your company and others’, and
- being generally agnostic as to whether humans or machines complete tasks in a given workflow.
I think every startup that competes with big clouds (read: every ambitious Infra startup) will need to carve out a space on which they are the undisputed independent source of truth, at least until the $100billion valuation stage when the metagame changes once more.
What’s the single most impactful project you’ve heard of an infrastructure engineering team working on? Why? Was it obviously impactful beforehand? Stripe’s Sorbet is an example of a discrete project that I found surprisingly impactful.
Probably the sharding system that became Vitess at YouTube. YouTube is quite simply the biggest social video platform on Earth today, but it faced a horde of well funded competitors in 2005-2010. YouTube was experiencing 2 outages a day due to the extreme load, and could have gone the way of Friendster if those performance issues continued. No Vitess, no YouTube.
Vitess made MySQL scalable for YouTube, then its open sourcing helped Hubspot, Slack, Pinterest, GitHub, Square and more. If database infra counts, then I’d be hard pressed to think of a more impactful project.
What are some resources (books, blogs, people, etc) you’ve learned from? Who are your role models in the field?
I keep a list of resources for DevTools and Dev Rel/Dev Community in my own space because the list of resources is long for such a young field. Special shoutouts to Beyang’s Guide to Devtools and Mary Thengvall’s Devrel Resources, and to Kelsey Hightower for getting me started Learning in Public and going down the Developer Advocate career path. Scott Hanselman is also a huge mentor to me, being an early reviewer of my book and with his inclusivity and ability to make anything in the Microsoft ecosystem interesting, and ability to cross over into newer platforms like Tiktok!